
Hey Twitter crowd … What else is there?
Original and shorter post at Crowdsearch.org.
Twitter is a powerful tool for journalists at multiple stages of the news production process: to detect newsworthy events, interpret them, or verify their factual veracity. In 2011, a poll on 478 journalists from 15 countries found that 47% of them used Twitter as a source of information. Journalists and news editors also use Twitter to contextualize and enrich their articles by examining the responses to them, including comments and opinions as well as pointers to other related news. This is possible because some users in Twitter devote a substantial amount of time and effort to news curation: carefully selecting and filtering news stories highly relevant to specific audiences.
We developed an automatic method that groups together all the users who tweet a particular news item, and later detects new contents posted by them that are related to the original news item. We call each group a transient news crowd. The beauty with this, in addition to be fully automatic, is that there is no need to pre-define topics and the crowd becomes available immediately, allowing journalists to cover news beats incorporating the shifts of interest of their audiences.
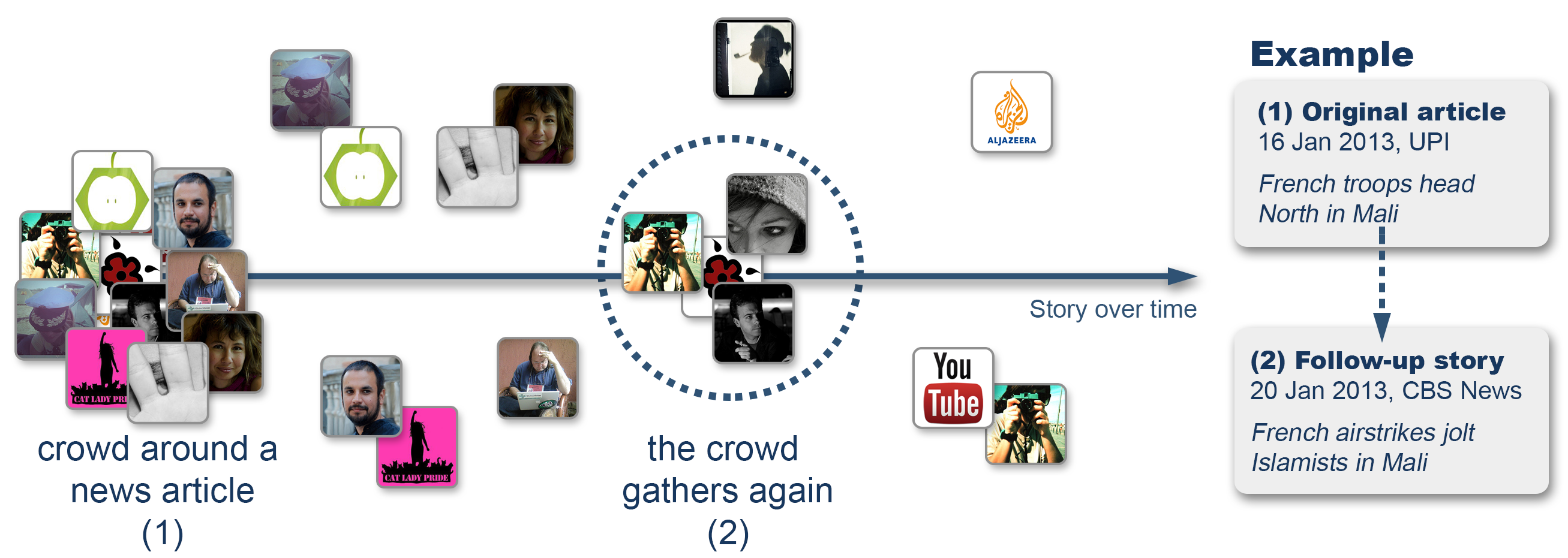 |
| Figure 1. Detection of follow-up stories related to a published article using the crowd of users that tweeted the article. |
Transient news crowds
In our experiments, we define the crowd of a news article as the set of users that tweeted the article within the first 6 hours after it is published. We followed users on each crowd during one week, recording every public tweet they posted during this period. We used Twitter data around news stories published by two prominent international news portals: BBC News and Al Jazeera English.
What did we find?
- After they tweet a news article, people’s subsequent tweets are correlated to that article during a brief period of time.
- The correlation is weak but significant, in terms of reflecting the similarity between the articles that originate a crowd.
- While the majority of crowds simply disperse over time, parts of some crowds come together again around new newsworthy events.
What can we do with the crowd?
Given a news crowd and a time slice, we want to find the articles in a given time slice that are related to the article that created the crowd. To accomplish this, we used a machine learning approach, which we trained on data annotated using crowd sourcing. We experimented with three types of features:
- frequency-based: how often an article is posted by the crowd compared to other articles?
- text-based: how similar are the two articles considering the tweets posted them?
- user-based: is the crowd focussed on the topic of the article? does it contain influential members?
We find that the features largely complement each other. Some features are always valuable, while others contribute only in some cases. The most important features include the similarity to the original story, as well as measures of how unique is the association of the candidate article and its contributing users to the specific story’s crowd.
Crowd summarisation
We illustrate the outcome of our automatic method with the article Central African rebels advance on capital, posted on Al Jazeera on 28 December, 2012.
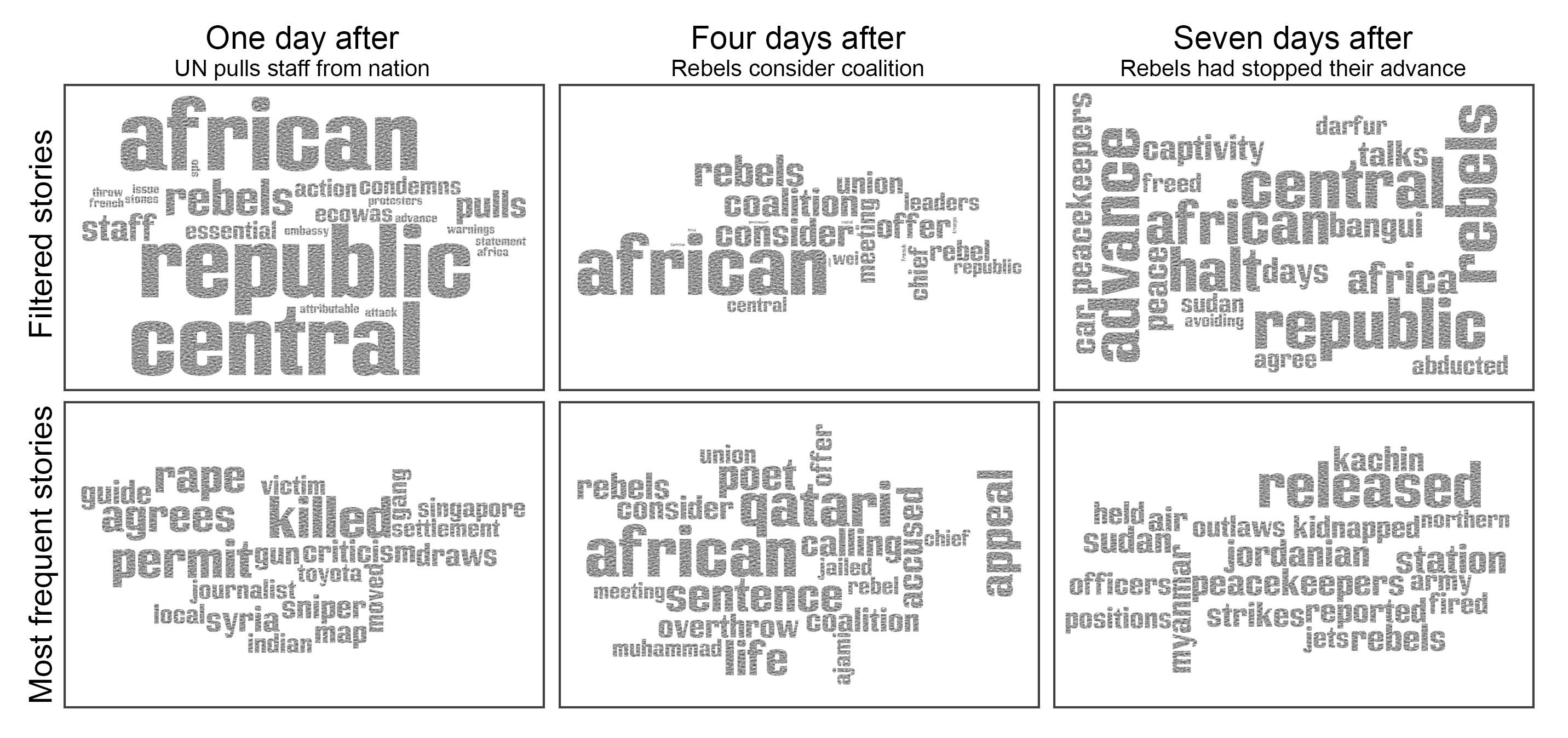 |
| Figure 2. Word clouds generated for the crowd on the article “Central African rebels advance on capital”, by considering the terms appearing in stories filtered by our system (top) and on the top stories by frequency (bottom). |
Without using our method (in the figure, bottom), we obtain frequently-posted articles which are weakly related or not related at all to the original news article. Using our method (in the figure, top), we observe several follow-up articles to the original one. Four days after the news article was published, several members of the crowd tweeted an article about the fact that the rebels were considering a coalition offer. Seven days after the news article was published, crowd members posted that rebels had stopped advancing towards Bangui, the capital of the Central African Republic.
News crowds allow journalists to automatically track the development of stories. For more details you can check our papers:
- Janette Lehmann, Carlos Castillo, Mounia Lalmas and Ethan Zuckerman: Transient News Crowds in Social Media. Seventh International AAAI Conference on Weblogs and Social Media (ICWSM), 8-10 July 2013, Cambridge, Massachusetts.
- Janette Lehmann, Carlos Castillo, Mounia Lalmas and Ethan Zuckerman: Finding News Curators in Twitter. WWW Workshop on Social News On the Web (SNOW), Rio de Janeiro, Brazil.
Janette Lehmann, Universitat Pompeu Fabra
Carlos Castillo, Qatar Computing Research Institute
Mounia Lalmas, Yahoo! Labs Barcelona
Ethan Zuckerman, MIT Center for Civic Media
