Story-focused reading in online news
I worked for several years with Janette Lehmann as part of her PhD looking at user engagement across sites. This blog post describes our work on inter-site engagement in the context of online news reading. The work was done in collaboration with Carlos Castillo and Ricardo Baeza-Yates [1].
Online news reading is a common activity of Internet users. Users may have different motivations to visit a news site: some users want to remain informed about a specific news story they are following, such as an important sport tournament or a contentious important political issue; others visit news portals to read about breaking news and remain informed about current events in general.
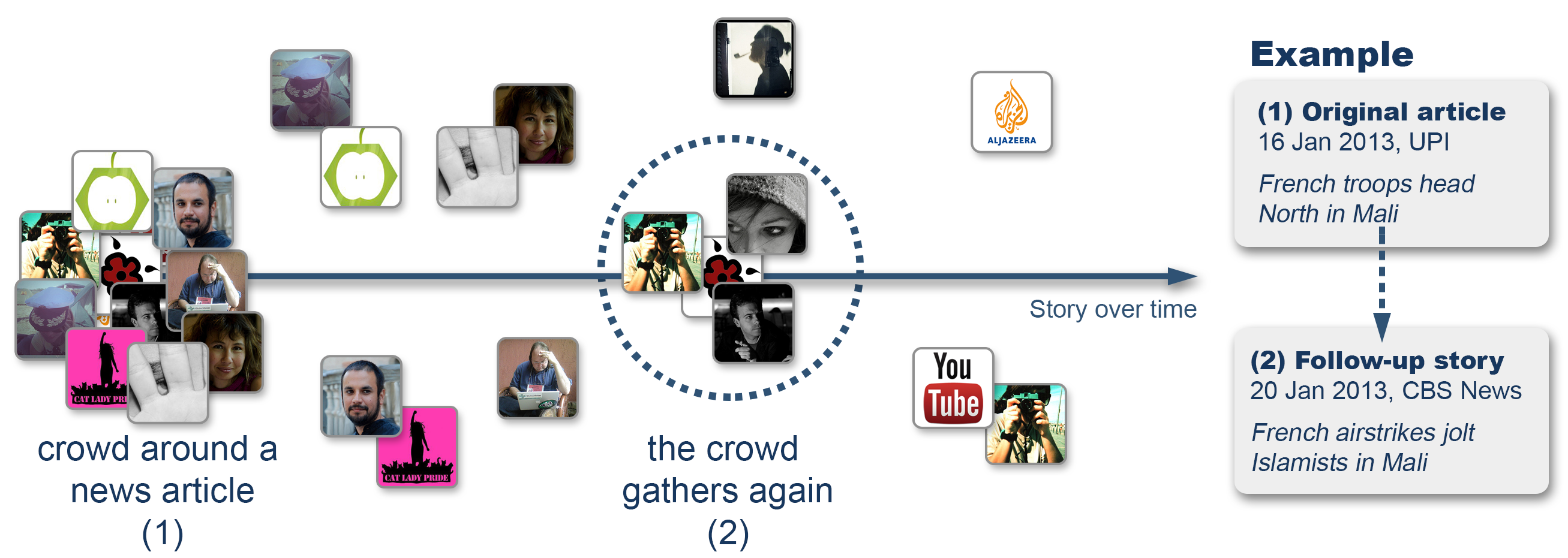
 While reading news, users sometimes become interested in a particular news item they just read, and want to find more about it. They may want to obtain various angles on the story, for example, to overcome media bias or to confirm the veracity of what they are reading. News sites often provide information on different aspects or components of a story they are covering. They also link to other articles published by them, and sometims even to articles published by other news sites or sources. An example of an article having links to others is shown on the right, at the bottom of the article.
While reading news, users sometimes become interested in a particular news item they just read, and want to find more about it. They may want to obtain various angles on the story, for example, to overcome media bias or to confirm the veracity of what they are reading. News sites often provide information on different aspects or components of a story they are covering. They also link to other articles published by them, and sometims even to articles published by other news sites or sources. An example of an article having links to others is shown on the right, at the bottom of the article.
We performed a large-scale analysis of this type of online news consumption: when users focus on a story while reading news. We referred to this as story-focused reading. Our study is based on a large sample of user interaction data on 65 popular news sites publishing articles in English. We show that:
- Story-focused reading exists, and is not a trivial phenomenon. This type of news reading differs from a user daily consumption of news.
- Story-focused reading is not simply a consequence of the fact that some stories are more popular, have more articles written about them, or covered by more news providers.
- Story-focused reading is driven by the interest of the users. Even users that can be considered as casual news readers (they only read few articles) engage in story-focused reading.
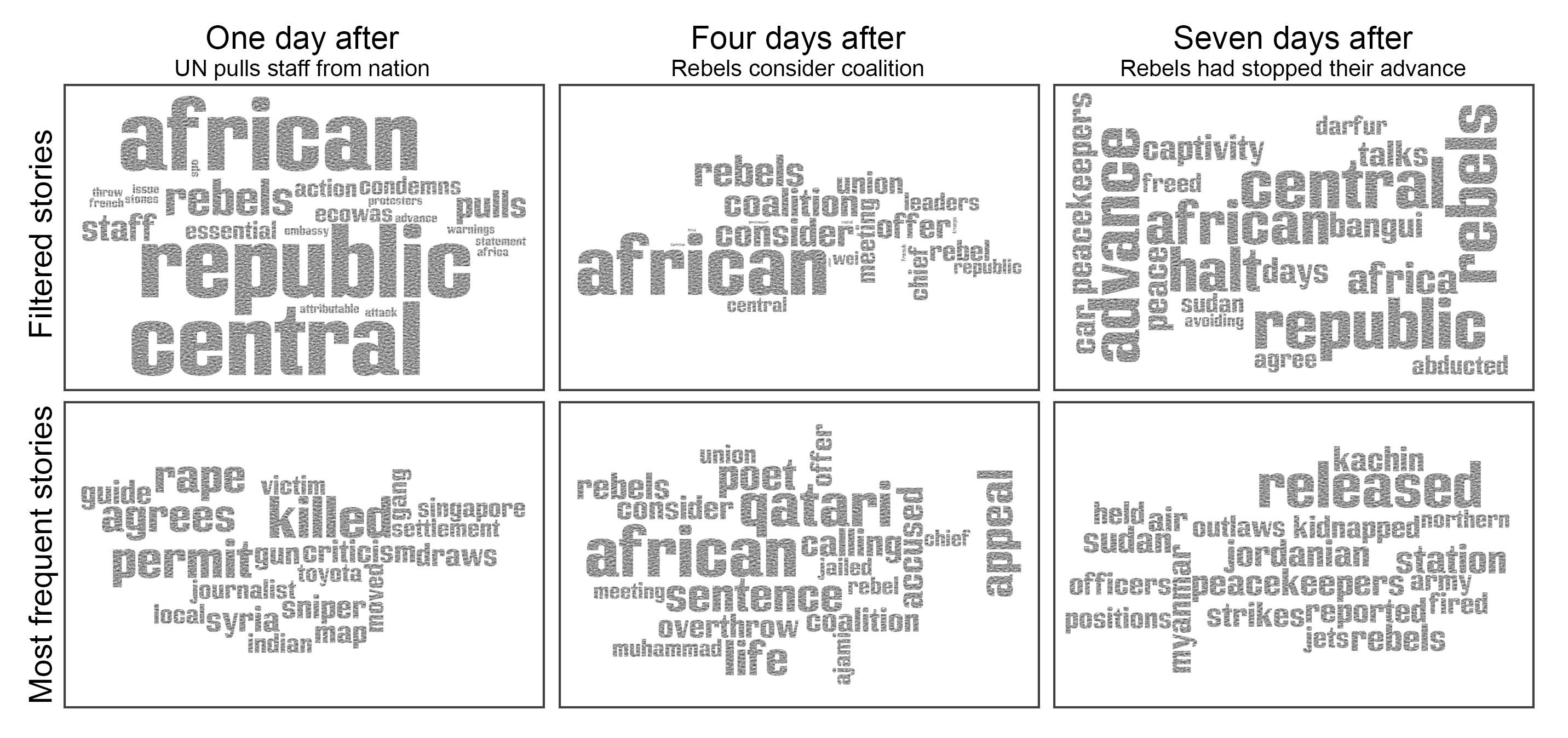
- When engaged in story-focused reading, users spend more time reading and visit more news providers. Only when users read many articles about a story, the reading time decreases. Our analysis suggests that this could be due to news articles containing mostly the same information.
The strategies that readers employ to find articles related to a story depend on how deep they want to delve into the story. If users are only reading a few articles about a story, they tend to gather all information from a single news site. In the case of deeper story-focused reading, where users are interested in the story details or specific information, they often use search and social media sites to access sites. Furthermore, many users are coming from less popular news sites and blogs, which makes sense, because blogs frequently link their posts to mainstream news sites when discussing an event and users are following these links to likely gather further information or confirm the veracity of what they are reading.
Strategies that keep users engaged with a news site include recommending news articles to users or integrating interactive features (e.g., multimedia content, social features, hyperlinks) into news articles. News providers can promote story-focused reading and increase engagement by linking their articles to other related content. Embedding links to related content into news articles and hyperlinks in general are an important factor that influences the stages of engagement (period of engagement, disengagement, and re-engagement). Having internal links within the article text promotes story-focused reading and as a result keeps users engaged:
It leads to a longer period of engagement (reading sessions are longer) and earlier re-engagement (shorter absence time). Providing links to external content does not have a negative effect on user engagement; the period of engagement remains the same (reading sessions are the same), and the re-engagement begins even sooner (shorter absence time).
This does not mean that news providers should just provide links; they should provide the right ones in terms of quantity and quality. The type, the position, and the number of links play an important role. Users tend to click on links that bring them to other news articles within the same news site, or to articles published by less known sources, probably because they provide new or less mainstream information. However, it is not a good strategy to offer too many such links, as this is likely to confuse or annoy users. Too many inline links can have detrimental effect on users’ reading experience. Finally, when engaged in story-focused reading, users tend to click on links that are close to the end of the article text.
The linking strategies of news providers affect the way users engage with their news sites, which by itself is not new. However, our results are in contradiction with the linking strategy that aims at keeping users as long as possible on a site by linking to other content on the site.
Instead, it can be beneficial (long-term) to entice users to leave the site (e.g., by offering them interesting content on other sites) in a way that users will want to return to it.
News providers could adapt their sites when they identify a user engaging in story-focused reading in various ways:
- Such information could be integrated in the personalised news recommender of the news site. Story-related articles in the news feed could be highlighted or content frames containing information and links related to the story could be presented on the front page.
- It might be also beneficial to provide and link to topic pages containing latest updates, background information, blog entries, eye witness reports, etc. related to the story.
Story-focused reading also brings new opportunities for news providers to drive traffic to their sites by collecting the most interesting articles and statements around a story, i.e., becoming a news story curator, and publishing them via social media channels or email newsletters.
- [1] J. Lehmann, C. Castillo, M. Lalmas and R. Baeza-Yates. Story-focused Reading in Online News and its Potential for User Engagement, Journal Of The Association For Information Science And Technology (JASIST), 2016.
 Recently, we were asked: “How engaged are Wikipedia users?” To answer this question, we visited
Recently, we were asked: “How engaged are Wikipedia users?” To answer this question, we visited  We collected 13 months (September 2011 to September 2012) of browsing data from an anonymized sample of approximately 1.3M users. We identified 48 actions such as reading an article, editing, opening an account, donating, visiting a special page. We then built a weighted action network: nodes are the actions and two nodes are connected by an edge if the two corresponding actions were performed during the same visit to Wikipedia. Each node has a weight representing the number of users performing the corresponding action (the node traffic). Each edge has a weight representing the number of users that performed the two corresponding actions (the traffic between the two nodes).
We collected 13 months (September 2011 to September 2012) of browsing data from an anonymized sample of approximately 1.3M users. We identified 48 actions such as reading an article, editing, opening an account, donating, visiting a special page. We then built a weighted action network: nodes are the actions and two nodes are connected by an edge if the two corresponding actions were performed during the same visit to Wikipedia. Each node has a weight representing the number of users performing the corresponding action (the node traffic). Each edge has a weight representing the number of users that performed the two corresponding actions (the traffic between the two nodes). Two important events happened in our 13-month period. During the donation campaign (November to December 2011) more users visited Wikipedia (higher TotalNodeTraffic value). We speculate that many users became interested in Wikipedia during the campaign. However, because TotalTrafficRecirculation actually decreased for the same period, although more users visited Wikipedia, they did not perform two (or more) actions while visiting Wikiepedia; they did not become more engaged with Wikipedia. However, during the SOPA/PIPA protest (January 2012), we see a peak in TotalNodeTraffic and TotalTrafficRecirculation. More users visited Wikipedia and many users became more engaged with Wikipedia; they also read articles, gathered information about the protest, donated money while visiting Wikipedia.
Two important events happened in our 13-month period. During the donation campaign (November to December 2011) more users visited Wikipedia (higher TotalNodeTraffic value). We speculate that many users became interested in Wikipedia during the campaign. However, because TotalTrafficRecirculation actually decreased for the same period, although more users visited Wikipedia, they did not perform two (or more) actions while visiting Wikiepedia; they did not become more engaged with Wikipedia. However, during the SOPA/PIPA protest (January 2012), we see a peak in TotalNodeTraffic and TotalTrafficRecirculation. More users visited Wikipedia and many users became more engaged with Wikipedia; they also read articles, gathered information about the protest, donated money while visiting Wikipedia. We detected different engagement patterns on weekdays and weekends. Whereas more users visited Wikipedia during weekdays (high value of TotalNodeTraffic), users that visited Wikipedia during the weekend were more engaged (high value of TotalTrafficRecirculation). On weekends, users performed more actions during their visits.
We detected different engagement patterns on weekdays and weekends. Whereas more users visited Wikipedia during weekdays (high value of TotalNodeTraffic), users that visited Wikipedia during the weekend were more engaged (high value of TotalTrafficRecirculation). On weekends, users performed more actions during their visits.![meaganmakes - 182-365+1 [cc] - 2](https://mounia-lalmas.blog/wp-content/uploads/2013/09/meaganmakes-182-3651-cc-2.png?w=300&h=225) So which actions became more frequent as a result of the donation campaign? As expected, we observed a significant traffic increase on the “donate” node during the two months; many users made a donation. In addition, the traffic from some nodes to other nodes increased but only slightly. Additional actions were performed; for instance, more users created a user account, visited community-related pages, all within the same session. However, overall, users mostly performed individual actions since TotalTrafficRecirculation decreased during that time period.
So which actions became more frequent as a result of the donation campaign? As expected, we observed a significant traffic increase on the “donate” node during the two months; many users made a donation. In addition, the traffic from some nodes to other nodes increased but only slightly. Additional actions were performed; for instance, more users created a user account, visited community-related pages, all within the same session. However, overall, users mostly performed individual actions since TotalTrafficRecirculation decreased during that time period.