
Online, users multitask
 We often access several sites within an online session. We may perform one main task (when we plan a holiday, we often compare offers from different travel sites, go to a review site to check hotels), or several totally unrelated tasks in parallel (responding to an email while reading news). Both are what we call online multitasking. We are interested in the extent to which multitasking occurs, and whether we can identify patterns.
We often access several sites within an online session. We may perform one main task (when we plan a holiday, we often compare offers from different travel sites, go to a review site to check hotels), or several totally unrelated tasks in parallel (responding to an email while reading news). Both are what we call online multitasking. We are interested in the extent to which multitasking occurs, and whether we can identify patterns.
Our dataset
Our dataset consists of one month of anonymised interaction data from a sample of 2.5 millions users who gave their consent to provide browsing data through a toolbar. We selected 760 sites, which we categorised according to the type of services they offer. Examples of services include mail, news, social network, shopping, search, and sometimes cater to different audiences (for example, news about sport, tech and finance). Our dataset contains 41 million sessions, where a session ends if more than 30 minutes have elapsed between two successive page views. Finally, continuous page views of the same site are merged to form a site visit.
How much multitasking in a session?
On average, 10.20 distinct sites are visited within a session, and for 22% of the visits the site was accessed previously during the session. More sites are visited and revisited as the session length increases. Short sessions have on average 3.01 distinct sites with a revisitation rate of 0.10. By contrast, long sessions have on average 9.62 different visited sites with a revisitation rate of 0.22.
We focus on four categories of sites: news (finance), news (tech), social media, and mail. We extract for each category a random sample of 10,000 sessions. As shown in Figure 1 below, the sites with the highest number of visits within a session belong to the social media category (average of 2.28), whereas news (tech) sites are the least revisited sites (average of 1.76). The other two categories have on average 2.09 visits per session.
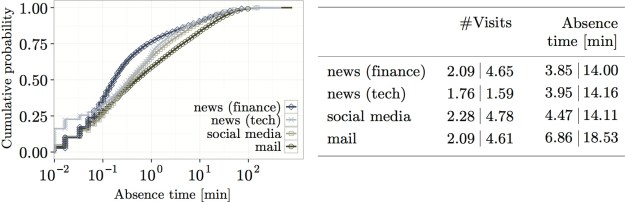 |
| Figure 1: Site visit characteristics for four categories of sites: (Left) Distribution of time between visits; and (Right) Average and standard deviation of number of visits and time between visits. |
What happens between the visits to a site?
We call the time between visits to a site within the session absence time. We see three main patterns with the four categories of sites, as shown in Figure 1 above (right):
- social media sites and news (tech) sites have an average absence time of 4.47 minutes and 3.95 minutes, respectively, although the distributions are similar;
- news (finance) sites have a skewer distribution, indicating a higher proportion of short absence time for sites in this category;
- mail sites have the highest absence time, 6.86 minutes on average.
However, the media of the distributions of the absence time across all categories of sites is less than 1 minute, and this for all categories. That is, many sites are revisited after a short break. We speculate that a short break corresponds to an interruption of the task being performed by the user (on the site), whereas a longer break indicates that the user is returning to the site to perform a new task.
How do users switch between sites?
Users can switch between sites in several ways:
- hyperlinking: clicking on a link,
- teleporting: jumping to a page using bookmarks or typing an URL, or
- backpaging: using the back button on the browser, or when several tabs or windows are ope and the user returns to one of them).
The way users revisit sites varies depending on the session length. Teleporting and hyperlinking are the most important mechanisms to re-access a site during short sessions (30% teleporting and 52% hyperlinking for short sessions), whereas backpaging becomes more predominant in longer sessions. Tabs or the back button are often used to revisit a site.
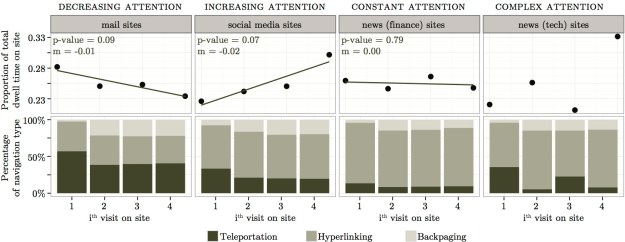 |
| Figure 2: (Top) Visit patterns described by the average time spent on the site at the ith visit in a session. (Bottom) Usage of navigation types described by the proportion of each navigation type at the ith visit in a session. |
We also look at how users access a site at each revisit, for the four categories of sites. This is shown in Figure 2 (bottom).
- For all four categories of sites, the first visit is often through teleportation. Accessing a site in this manner indicates a high level of engagement, in particular in terms of loyalty, with the site, since users are likely to have bookmarked the site at some previous interaction with it. In our dataset, teleportation is more frequently used to access news (tech) sites than news (finance) sites.
- After the first visit, backpaging is increasingly used to access a site. This is an indication that users leave the site by opening a new tab or window, and then return to the site later to continue whatever they were doing on the site.
- However, in general, users still revisit a site mostly through hyperlinking, suggesting that links still have an important role in directing users to a site. In our dataset, news (finance) sites are mostly accessed through links; users are directed to sites of this category via a link.
Time spent at each revisit
For each site, we select all sessions where the site was visited at least four times. We see four main patterns, which are shown in Figure 2 (top):
- The time spent on social media sites increases at each revisit (a case of increased attention). The opposite is observed for mail sites (a case of decreased attention). A possible explanation is that, for mail sites, there are less messages to read in subsequent visits, whereas for social media sites, users have more time to spend on them eventually because the other tasks they were doing are getting finished.
- News (finance) is an example of category for which neither a lower or higher dwell time is observed at each subsequent revisit (a case of constant attention). We hypothesise that each visit corresponds either to a new task or a user following some evolving piece of information such as checking the latest stock price figures.
- The time spent on news (tech) sites at each revisit is fluctuating. Either no patterns exist or the pattern is complex, and cannot easily be described (a case of complex attention). However, when looking at the first two visits or the last two visits, in both cases, more time is spent in each second visit. This may indicate that the visits belong to two different tasks, and each task is performed in two distinct visits to the site. Teleportation is more frequent at the 1st and 3rd visits, which confirms this hypothesis (Figure 2, bottom).
Take away message
Multitasking exists, as many sites are visited and revisited during a session. Multitasking influences the way users access sites, and this depends on the type of site.
This work was done in collaboration with Janette Lehmann, Georges Dupret and Ricardo Baeza-Yates. More details about the study can be found in Online Multitasking and User Engagement, ACM International Conference on Information and Knowledge Management (CIKM 2013), 27 October – 1 November 2013, San Francisco, USA.
Photo credits: D&D (Creative Commons BY).
 Recently, we were asked: “How engaged are Wikipedia users?” To answer this question, we visited
Recently, we were asked: “How engaged are Wikipedia users?” To answer this question, we visited  We collected 13 months (September 2011 to September 2012) of browsing data from an anonymized sample of approximately 1.3M users. We identified 48 actions such as reading an article, editing, opening an account, donating, visiting a special page. We then built a weighted action network: nodes are the actions and two nodes are connected by an edge if the two corresponding actions were performed during the same visit to Wikipedia. Each node has a weight representing the number of users performing the corresponding action (the node traffic). Each edge has a weight representing the number of users that performed the two corresponding actions (the traffic between the two nodes).
We collected 13 months (September 2011 to September 2012) of browsing data from an anonymized sample of approximately 1.3M users. We identified 48 actions such as reading an article, editing, opening an account, donating, visiting a special page. We then built a weighted action network: nodes are the actions and two nodes are connected by an edge if the two corresponding actions were performed during the same visit to Wikipedia. Each node has a weight representing the number of users performing the corresponding action (the node traffic). Each edge has a weight representing the number of users that performed the two corresponding actions (the traffic between the two nodes). Two important events happened in our 13-month period. During the donation campaign (November to December 2011) more users visited Wikipedia (higher TotalNodeTraffic value). We speculate that many users became interested in Wikipedia during the campaign. However, because TotalTrafficRecirculation actually decreased for the same period, although more users visited Wikipedia, they did not perform two (or more) actions while visiting Wikiepedia; they did not become more engaged with Wikipedia. However, during the SOPA/PIPA protest (January 2012), we see a peak in TotalNodeTraffic and TotalTrafficRecirculation. More users visited Wikipedia and many users became more engaged with Wikipedia; they also read articles, gathered information about the protest, donated money while visiting Wikipedia.
Two important events happened in our 13-month period. During the donation campaign (November to December 2011) more users visited Wikipedia (higher TotalNodeTraffic value). We speculate that many users became interested in Wikipedia during the campaign. However, because TotalTrafficRecirculation actually decreased for the same period, although more users visited Wikipedia, they did not perform two (or more) actions while visiting Wikiepedia; they did not become more engaged with Wikipedia. However, during the SOPA/PIPA protest (January 2012), we see a peak in TotalNodeTraffic and TotalTrafficRecirculation. More users visited Wikipedia and many users became more engaged with Wikipedia; they also read articles, gathered information about the protest, donated money while visiting Wikipedia. We detected different engagement patterns on weekdays and weekends. Whereas more users visited Wikipedia during weekdays (high value of TotalNodeTraffic), users that visited Wikipedia during the weekend were more engaged (high value of TotalTrafficRecirculation). On weekends, users performed more actions during their visits.
We detected different engagement patterns on weekdays and weekends. Whereas more users visited Wikipedia during weekdays (high value of TotalNodeTraffic), users that visited Wikipedia during the weekend were more engaged (high value of TotalTrafficRecirculation). On weekends, users performed more actions during their visits.![meaganmakes - 182-365+1 [cc] - 2](https://mounia-lalmas.blog/wp-content/uploads/2013/09/meaganmakes-182-3651-cc-2.png?w=300&h=225) So which actions became more frequent as a result of the donation campaign? As expected, we observed a significant traffic increase on the “donate” node during the two months; many users made a donation. In addition, the traffic from some nodes to other nodes increased but only slightly. Additional actions were performed; for instance, more users created a user account, visited community-related pages, all within the same session. However, overall, users mostly performed individual actions since TotalTrafficRecirculation decreased during that time period.
So which actions became more frequent as a result of the donation campaign? As expected, we observed a significant traffic increase on the “donate” node during the two months; many users made a donation. In addition, the traffic from some nodes to other nodes increased but only slightly. Additional actions were performed; for instance, more users created a user account, visited community-related pages, all within the same session. However, overall, users mostly performed individual actions since TotalTrafficRecirculation decreased during that time period. I recently attended the
I recently attended the  Common measurements include:
Common measurements include:
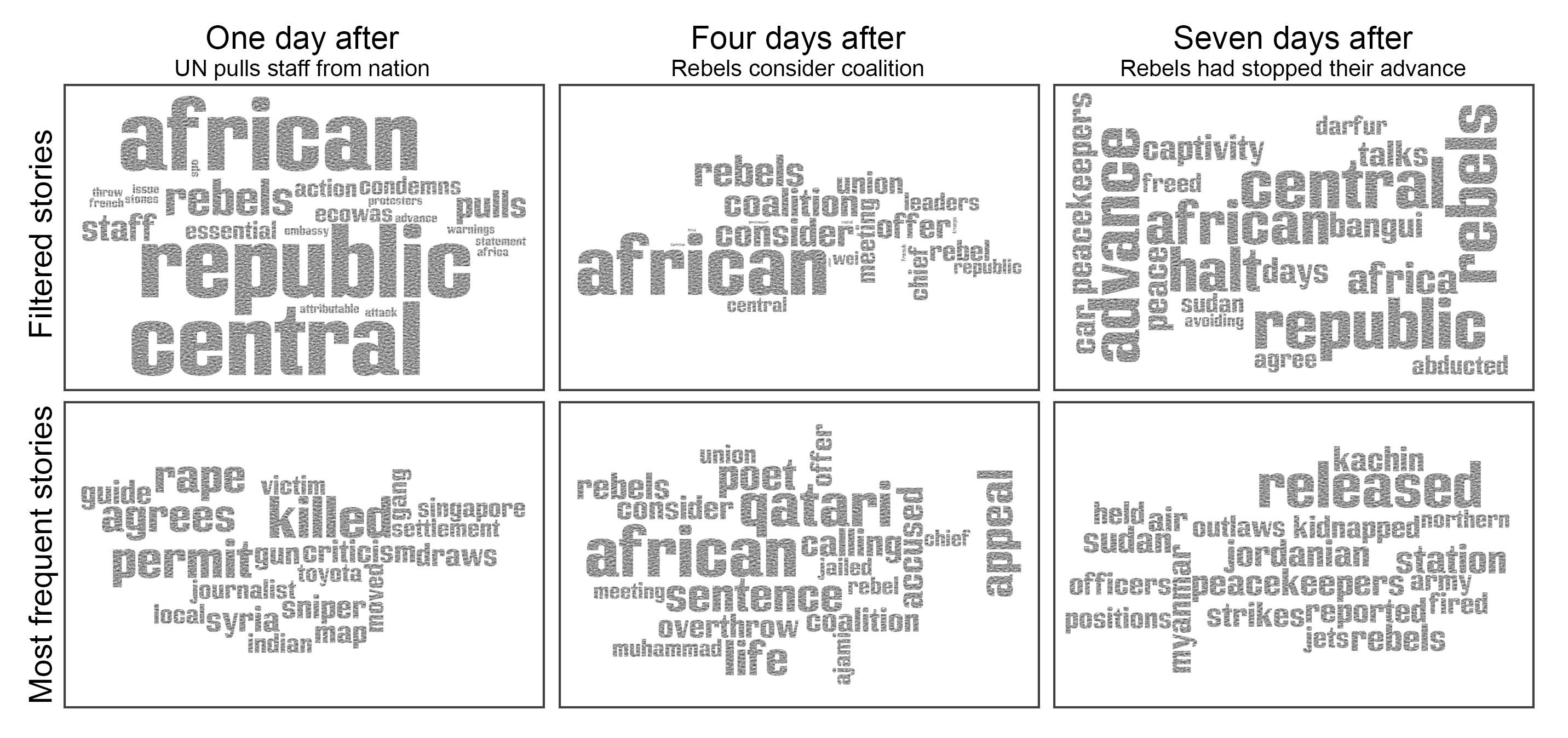
 Measure: Absence time
Measure: Absence time  A small warning
A small warning
 What did we do?
What did we do?  … So what now?
… So what now?